AI时代-汹涌而来
回望2023,真的是魔幻的一年。
游戏圈有魔界咕噜、浩劫前夕等雪山扑面而来,搞得我们这些游戏玩家措手不及,也让诸多赛博食雪汉们争先恐后、前仆后继,让我真正意识到了什么是为了流量可以:明知山有雪,雪中悍刀行。当然,这么搞,也是辛苦他们了
同样的,在2023年,AI 圈也是成了一锅大乱炖。从年初的 OpenAI 推出的 GPT-4,到文心一言、通义千问再到讯飞的星火大模型,从绘画大神DELL-E 再到 Midjourney,以及各种各样其他名不见经传的小模型。无时无刻都在宣读着 AI 对于人类艺术的入侵,人类引以为傲的艺术将受到前所未有的挑战。
AI化并不是一蹴而就的,从最开始基于广大数据量发展而来的 Siri、播到语音输入以及小爱同学。
而23准确说是22年所带来的 chatGPT ,才让人真正感觉到了恐惧.
一个 AI 居然能够和人正常的聊天、读书、写作、写代码、解决情感问题、通过雅思口语考试。
这就是新时代 AI 的威力。
它不再仅仅局限于厂家的几句设定所带来的刻板的回复。
像是真人一样拥有了感情。
而这一切,都归功于大模型和 GPT
什么是GPT?
这个问题还是要 chatGPT 自己来回答比较好
看来我们 chat GPT 回答的已经相当完备了,那我这里就不再插嘴了,我们继续。
各位大佬们别看预训练是模型吹的玄乎玄乎的,充其量不过是填鸭式的塞入数据,然后猜用户要说什么,猜对了的话,喜大普奔,皆大欢喜。要错了的话,顶多就挨几句骂,仅此而已。
而 GPT 唯一的亮点:就是自然语言和后文猜测
支撑这些猜测运行的就是:大模型
大模型,就是参数超级多的机器学习模型。参数越多,模型就越聪明。
- 其中有以下特别出名的大模型:
- GPT-3:参数1750亿,由OpenAI开发。
- LaMDA:参数137B,由Google AI开发
- WuDao 2.0:参数1.75万亿,由百度开发。
- Megatron-Turing NLG:参数537B,由谷歌、微软、OpenAI等公司联合开发。
反观国内的大模型,不能说差强人意,也只能说是一言难尽
国内大模型
2023是国内大模型百花齐放的一年,正所谓一花齐放不是春,百花齐放春满园,我是非常乐意看到我国科技的进步,同时,我也非常仰慕外国的科技进步,不像某些国外友人那样子发新品了之后就在那拆手机。
其实,国内做大模型应该挺受人尊敬的,毕竟,这表明了我们可能站在了世界的前列,类似于某度的文心一言,阿里的通义千问,腾讯的混元甚至于复旦大学的MOSS(小苔藓)还有中科院的紫东太初【不过链接好像404了】
这似乎都在表明我国的AI大模型正在蓬勃发展!
具体的测试已经有B站大佬做出来了,我就不搞了。

bilibili-5大AI模型测评,带你一天上班摸鱼4小时!
上半年发布的AI大模型太多了,至少有好几百个,有时候一次展会就有100个模型参展,太夸张了。如果要用AI来提升生产力,到底哪个AI模型最好用?今天,就给大家带来5款常见的世界顶级免费大语言模型的横向测评。
【似乎】,这个词很耐人寻味
到底如何?为什么要用似乎?
问题
回望中文互联网走来的磕磕绊绊,就会发现,中文互联网其实一直有一种情况:充斥这我这样没有任何水平的创作者,【罕见的自知之明】,简称:低质创作者。他们每为中文互联网大量输出无效内容,其中,最经几年接着短视频的东风,这种风气就愈发盛行。免费给你一个话筒,你不说一点?
就如此,多入山般的数据干扰了中文互联网的环境,这也导致你与bard对话中出现的:“百度文心一言”问题了,这是用AI来训练AI。
很可惜的是的: 截止本文写稿时,google已经将这个错误修复了
但没说不可以不讲武德
同样的套路我们还可以在bard上面玩!
相信我,这会很有趣的
emm,看来Google修了,但没有完全修。
这次应该大家都是来看乐子的,应该不会有AI从业者跑完这个灌满水的小破站来照镜子吧?不会吧,不会吧。
这其实是中文大模型中一个很大的问题,大到连Google这样的大公司也要依靠国内的文心一言来训练他们的中文语料AI【也不排除是GFW的问题】
中文语料污染/中文语料低质的问题
污染问题其实很早以前就开始了,你也可以理解为外地的文化渗透以及国内平台的监管问题,平台禁止网页搜索引擎的爬虫爬取站点,禁止用户外链等问题,让本来就很大的中文互联网的链接性大大减弱,资源也更加难以收集。
其次就是语料低质的问题。
这个问题其实也是很早就有的,从贴吧时代开始,到百度问问的结束,再到现在的短视频的爆火,从最早的网络博客【就是我现在在玩的东西】,到微博时代,再到现在的微信朋友圈。人们可以发言的地方变多了,加之各种所谓的创作激励,导致各种各样的标题党以及假新闻的出现。各种“典”、“孝”、“急”、“乐”等在互联网上盛行,
这些在没有AI的时候都是小问题,毕竟,没人对你的资料感兴趣,也没人回专门去研究你的个人兴趣
但,一旦在搜索引擎和AI的加持下,一切都混乱了起来。AI客不管你是不是个人,互联网上的数据,他一件一件地照单全收,在一定的情况下根本没有人介入。可以看一下下面的的图片
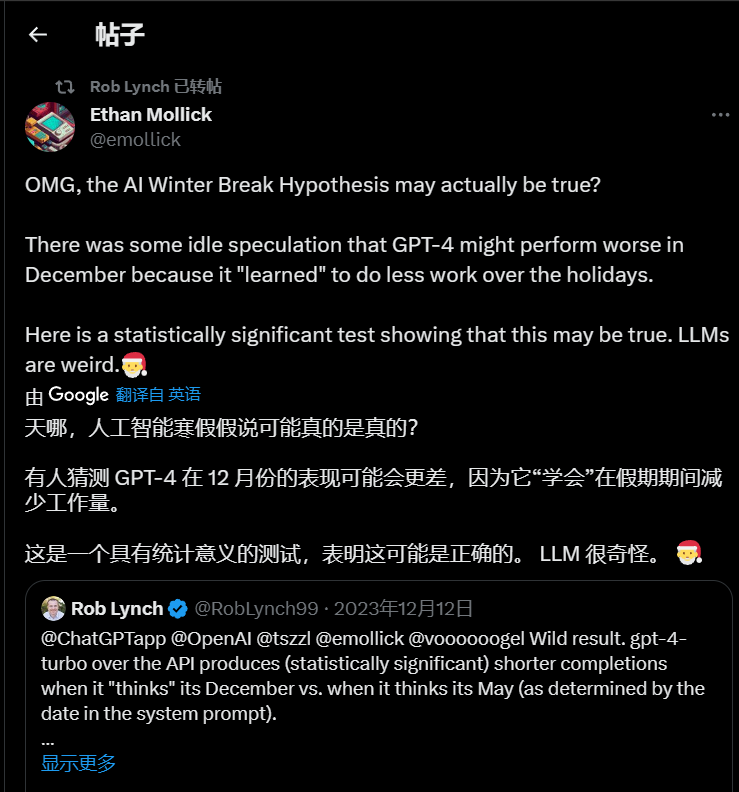
在X上Ethan Mollick的帖子:
OMG, the AI Winter Break Hypothesis may actually be true?【天哪,人工智能寒假假说可能真的是真的?】
嗯嘛嘛,那是不是说明,我们的AI在晚上九点的效率最高?因为这个时候美国那边块放假了,AI也要开始度假了
希望不是吧
其实,上面这张图片所讲述的就是现在生成式大模型的一个通病
,当他收取了过多当地的文化习俗就会出现谓之"给小费"用来提升AI生成的文本长度的方法。这也就是为什么我们的中文语料会影响AI的结果吧,相信你也不想看到:
只是演绎,请勿当真。
one move thins
中文AI还有很长的路要走,但我们无可否认的是:中文AI的缺占有一席之地了。在现在的国际AI都是中译英在翻译为中文的操作要高端一些。
我们将要面对的是AI对人类经济、政治、文化的全方位入侵,以及在抖音等短视频平台的推广之下的AI主播、AI视频无底线的擦边博眼球和赚流量等问题,以及将来的AI训练AI,人类不产出任何内容。AI换脸等技术的发展使眼见为实的时代在2023正式宣告了它的死亡。
还有
、隐私泄露、思维控制等诸多问题。都等着我们去探索
我们只要记住:
工具是没有对错的,有对错的是使用它的人!!!